






Kết thúc bước EFA, chúng ta sẽ tiến hành tạo nhân tố đại diện (biến đại diện) phục vụ cho bước phân tích tương quan quan, hồi quy, phương sai…
Mục đích cuối cùng của phần phân tích định lượng là trả lời cho các giả thuyết đặt ra: các biến độc lập có sự tác động lên biến phụ thuộc hay không. Bởi vì các biến độc lập và phụ thuộc là các khái niệm trừu tượng, chúng ta mới xây dựng các thang đo biến quan sát để làm công cụ đo lường trung gian. Tuy nhiên, không phải lúc nào các biến quan sát cho mỗi nhân tố chúng ta xây dựng đều có ý nghĩa trong thang đo, chúng ta cần thực hiện kiểm định độ tin cậy Cronbach’s Alpha và phân tích nhân tố EFA để chọn lọc giữ lại các biến quan sát tốt và loại bỏ các biến quan sát kém chất lượng. Kết thúc bước chọn lọc, chúng ta có được các nhân tố phù hợp nhất với các biến quan sát tốt nhất. Lúc này, chúng ta sẽ cần chuyển hướng việc đo lường biến quan sát về đo lường nhân tố để kết luận được các giả thuyết đặt ra, bước chuyển đổi này được gọi là tạo nhân tố đại diện.

Sau EFA, chúng ta có được các nhân tố giống hoặc không giống với cấu trúc nhân tố lý thuyết. Chúng ta thực hiện tạo nhân tố đại diện dựa trên kết quả ma trận xoay EFA cuối cùng. Bên dưới là bảng tổng hợp các nhân tố sau phân tích EFA và ký hiệu mã hóa nhân tố đại diện:
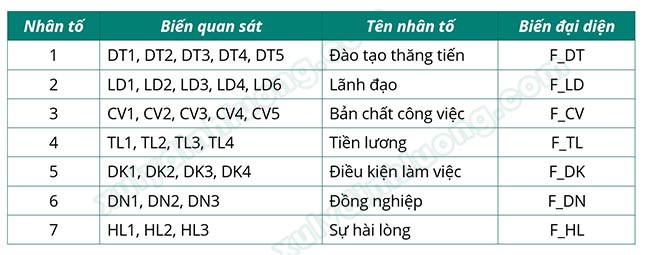
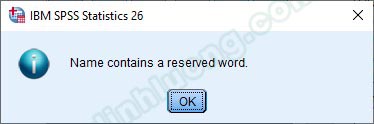
Khi đặt ký hiệu cho nhân tố đại diện (biến đại diện), chúng ta nên thêm tiền tố “F_” trước ký hiệu để tránh trùng ký tự đặc biệt trong SPSS trong một số trường hợp. Nếu tên biến được khai báo vi phạm nguyên tắc của SPSS, một bảng thông báo “Name contain a reserved word” sẽ xuất hiện.
Có ba cách tạo biến đại diện được sử dụng hiện nay, chúng ta sẽ lần lượt đi qua từng cách với ví dụ minh họa.
1. Tạo nhân tố đại diện bằng trung bình cộng
Biến đại diện được tạo bằng cách tính trung bình cộng các biến quan sát của nhân tố đó. Với các nghiên cứu sử dụng thước đo Likert, hay các thước đo ảo với giá trị đo là số nguyên thì cách xây dựng biến đại diện bằng cách này rất phù hợp. Nó sẽ giúp ích cho nhà nghiên cứu có thể triển khai các bước phân tích sau hồi quy mà không gặp nhiều khó khăn. Từ bảng tổng hợp các nhân tố sau phân tích EFA, trên giao diện SPSS, chúng ta vào Transform > Compute Variables…
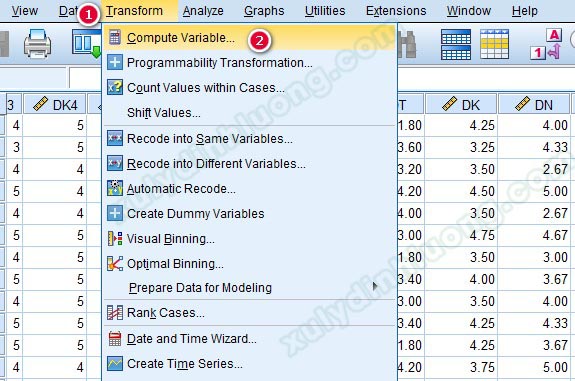
Một cửa sổ mới được mở ra, chúng ta chú ý tới 2 mục là Target Variable bên trái và khung nhập hàm Numeric Expression bên phải:
- Target Variable: Điền tên biến đại diện. Cụ thể ở đây là nhân tố F_TL.
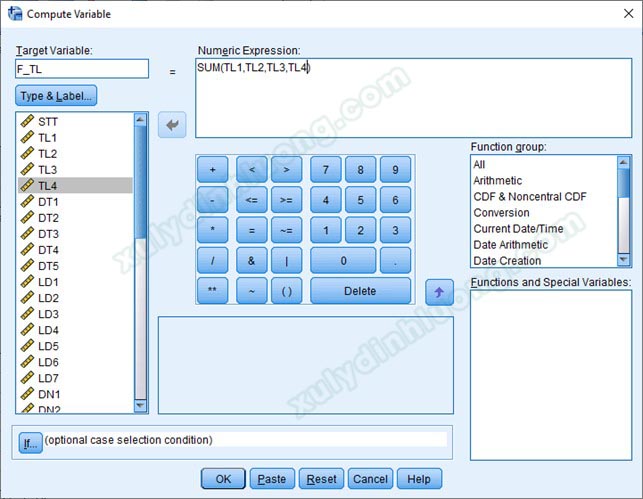
- Numeric Expression: Nhập hàm MEAN(giá trị 1,giá trị 2,giá trị 3,…). Cụ thể ở đây là MEAN(TL1,TL2,TL3,TL4). Tên hàm có thể viết hoa hoặc viết thường, các giá trị trong hàm ngăn cách nhau bằng dấu phẩy và không có khoảng cách trắng.
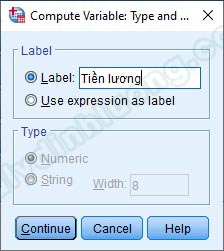
Khi khai báo tên biến, chúng ta có thể vào Type & Label để nhập nhãn biến. Phần này không bắt buộc, có thể điền hoặc không điền.
Sau khi khai báo biến, hàm, nhãn biến, nhấp vào OK để xác nhận hoàn thành. Lúc này quay lại giao diện Variable View của SPSS, sẽ có một biến mới được tạo ra tên là F_TL. Thực hiện tương tự cho các biến còn lại, chúng ta sẽ có danh sách biến đại diện như bên dưới.
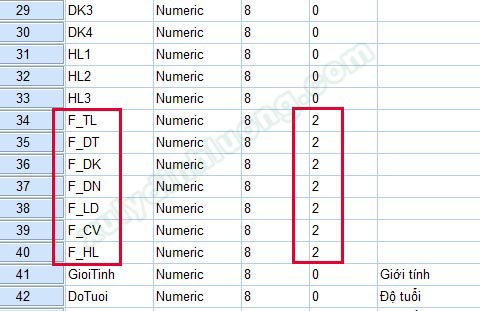
Sau khi đã hoàn thành việc tạo biến đại diện, chúng ta nên quay lại giao diện Variable View, chỉnh Decimals cho các biến đại diện là 2. Biến đại diện là trung bình của nhiều biến quan sát nên thường kết quả sẽ trả về số thập phân, nếu chúng ta để Decimals về 0 sẽ không hợp lý lắm vì ta đã làm tròn về dạng số nguyên. Do vậy, chúng ta nên làm tròn 2 chữ số thập phân, nhìn vào kết quả sẽ hợp lý và tự nhiên hơn.
Ưu điểm: dễ hiểu, có thể ứng dụng nhân tố đại diện cho nhiều phân tích khác, đặc biệt là phân tích khác biệt trung bình sẽ được giới thiệu ở chương 13.
Nhược điểm: không xét đến vai trò đóng góp của các biến quan sát trong nhóm, tầm quan trọng các biến quan sát đều được đánh đồng như nhau.
2. Tạo nhân tố đại diện bằng tổng giá trị
Thay vì tính trung bình cộng giá trị các biến quan sát thuộc nhân tố, chúng ta cũng có thể tạo biến đại diện bằng tổng giá trị các biến quan sát đó. Cách thực hiện tương tự như tạo nhân tố đại diện bằng trung bình cộng, chúng ta vào Transform > Compute Variables… Lần lượt nhập tên biến vào Target Variable, nhập nhãn biến vào Type & Label, và nhập hàm tính vào Numeric Expression. Lúc này, thay vì nhập hàm trung bình cộng MEAN, chúng ta sẽ sử dụng hàm tổng SUM theo cấu trúc SUM(giá trị 1,giá trị 2,giá trị 3,…). Cụ thể ở đây là SUM(TL1,TL2,TL3,TL4). Tên hàm có thể viết hoa hoặc viết thường, các giá trị trong hàm ngăn cách nhau bằng dấu phẩy và không có khoảng cách trắng.
Với cách tạo biến đại diện này, hầu hết các phân tích về sau đều cho ra kết quả giống với cách tính từ trung bình cộng. Do vậy, nhà nghiên cứu chỉ cần chọn một trong hai cách để sử dụng.
Ưu điểm: dễ hiểu, có thể ứng dụng nhân tố đại diện cho nhiều phân tích khác.
Nhược điểm: không xét đến vai trò đóng góp của các biến quan sát trong nhóm, tầm quan trọng các biến quan sát đều được đánh đồng như nhau.
3. Tạo nhân tố đại diện bằng điểm nhân tố
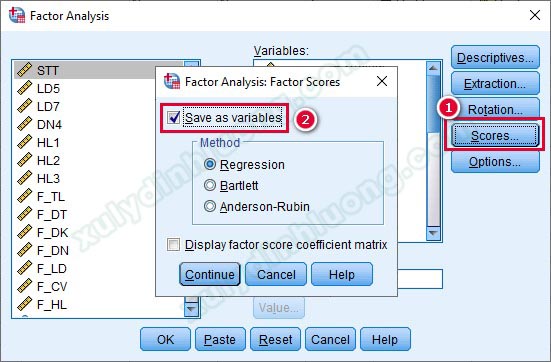
Phương thức này mang nhiều khác biệt so với hai cách ở trên. Nếu dùng trung bình cộng và tổng, sự đóng góp các biến quan sát trong nhân tố không được xét đến thì với cách thứ ba này, nhân tố đại diện phản ánh chính xác nhất đặc điểm của các biến quan sát. Những biến quan sát có hệ số tải cao, nghĩa là có đóng góp nhiều vào nhân tố sẽ được tính điểm nhiều hơn vào biến đại diện. Để thực hiện tạo nhân tố đại diện bằng điểm nhân tố, tại giao diện Factor Analysis, chúng ta vào Scores…, sau đó tích vào mục Save as variables.
Lưu ý, với phương thức này, chúng ta chỉ thực hiện bước tạo biến đại diện sau lần phân tích EFA cuối cùng, bởi mỗi lần chúng ta thực hiện EFA, biến đại diện lại được tạo ra. Nếu bạn cần loại nhiều biến xấu cần phân tích nhiều lần EFA, mỗi lần như vậy SPSS sẽ tạo ra các biến đại diện dựa vào kết quả ma trận xoay. Số biến đại diện không hoàn chỉnh sẽ tạo ra liên tục đến khi bạn ngưng phân tích EFA, lúc này trong khuôn dữ liệu của bạn sẽ có rất nhiều biến đại diện không dùng đến. Việc này không ảnh hưởng đến kết quả phân tích, tuy nhiên về mặt thẩm mỹ và tính trực quan, chúng ta không nên để xuất hiện quá nhiều biến thừa trong dữ liệu.
Ưu điểm: nhân tố đại diện được xây dựng dựa trên mức độ đóng góp của các biến quan sát, nhờ vậy, nhân tố biểu thị tốt đặc điểm của các biến quan sát hơn.
Nhược điểm: biến đại diện được tạo chỉ sử dụng vào phân tích hồi quy tuyến tính; ngoài ra, các biến đại diện đều đã được chuẩn hóa nên chúng ta không đánh giá được một số giả định trong hồi quy quan trọng.











0 nhận xét:
Đăng nhận xét