1. Phân tích nhân tố khẳng định để làm gì?
Phân tích nhân tố khẳng định - Confirmatory Factor Analysis (CFA) là kiểm định được sử dụng để thực hiện các mục đích sau:
- Đánh giá được độ phù hợp tổng thể của dữ liệu dựa trên các chỉ số độ phù hợp mô hình (model fit) như Chisquare/df, CFI, TLI, GFI, RMSEA...
- Đánh giá chất lượng biến quan sát, khẳng định các cấu trúc nhân tố. Nếu EFA làm nhiệm vụ khám phá cấu trúc nhân tố từ một tập hợp các biến quan sát đưa vào và giả định chưa biết biến nào nằm chung trong một thang đo (chung một nhân tố) thì CFA lại khác khá nhiều. Các biến quan sát đưa vào phân tích CFA được giả định là đã xác định được biến quan sát nào thuộc thang đo nào rồi và chức năng của CFA lúc này là đánh giá xem các biến quan sát trong nội bọ thang đo đó đã phù hợp chưa, đạt tiêu chuẩn chưa.
- Đánh giá tính hội tụ, tính phân biệt các cấu trúc biến.

2. Biểu diễn cấu trúc biến lên diagram CFA
Để phân tích CFA, chúng ta cần biểu diễn biến lên diagram. Phần mềm AMOS là công cụ yêu cầu người dùng vẽ thủ công hoàn toàn diagram. Việc này mất thời gian và công sức khá nhiều, do vậy một số nhà phát triển đã xây dựng nên plugin Pattern Matrix Builder để đưa biến vào AMOS nhanh hơn từ ma trận xoay EFA.
Cần lưu ý rằng, plugin là công cụ hỗ trợ rút ngắn thao tác, không phải không có plugin thì chúng ta không vẽ được diagram SEM. Kèm với đó, EFA là một kiểm định, CFA là một kiểm định, chúng có liên quan nhau nhưng không phải là mối quan hệ nhân quả. Không phải phải thực hiện EFA thì mới triển khai được CFA, không phải cần có ma trận xoay thì mới vẽ được diagram CFA. AMOS là phần mềm được phát triển với đầy đủ công cụ vẽ diagram mà không cần bất cứ plugin hay yếu tố đầu vào từ EFA.
Do đó, nếu gặp các vấn đề khi cài đặt plugin hoặc plugin sử dụng không ổn định, các bạn nên vẽ thủ công diagram bằng công cụ có sẵn của AMOS. Xem chi tiết cách sử dụng công cụ AMOS qua video bên dưới.
3. Tải và cài đặt plugin Pattern Matrix Builder
Như vừa trình bày ở phần trước, các nhà phát triển đã xây dựng nên plugin để rút ngắn rút ngắn thời gian vẽ thủ công. Plugin Pattern Matrix Builder giúp đưa nhanh diagram từ ma trận xoay EFA vào AMOS. Do không phải lúc nào ma trận EFA cũng cùng số lượng nhân tố, cùng số lượng biến quan sát với diagram CFA cần vẽ, nên chúng ta cần linh hoạt sử dụng plugin một cách hiệu quả theo hướng dẫn ở video sau:
Các bạn cần sử dụng phiên bản plugin tương ứng với phiên bản phần mềm AMOS đang có. Bạn tải và cài đặt phần mềm + plugin theo các link bên dưới:
- Plugin Pattern Matrix Builder dành cho AMOS 20: link tại đây
- Plugin Pattern Matrix Builder dành cho AMOS 24: link tại đây
4. Phân tích nhân tố khẳng định CFA

Cấu trúc biến:
- QC gồm 5 biến quan sát.
- QH gồm 5 biến quan sát.
- KM gồm 4 biến quan sát.
- BH gồm 6 biến quan sát. Trong đó BH6 bị loại ở bước EFA.
- NB gồm 4 biến quan sát.
- TT gồm 5 biến quan sát.
Khởi động phần mềm AMOS, click chọn vào biểu tượng Select Data file như hình bên dưới:

Tại cửa sổ hiện ra, chọn File Name, sau đó chọn file dữ liệu SPSS đầu vào.

Trong ví dụ này, file dữ liệu có tên là DATA AMOS.sav. Sau khi chọn xong file dữ liệu, chọn vào Open để kết thúc thao tác.

Tiếp tục nhấp vào OK để AMOS nhận file dữ liệu SPSS.

Quay về cửa sổ chính phần mềm AMOS, vẽ diagram cấu trúc biến vào AMOS như bên dưới. Chúng ta có thể vẽ thủ công hoặc dùng plugin để rút ngắn thao tác.

Bài viết này sẽ hướng dẫn dùng plugin, phần vẽ thủ công các bạn tự tìm hiểu ở mục số 2 bên trên.
Tiến hành vẽ diagram Vào Plugins > Pattern Matrix Model Buider

Chúng ta sẽ lấy bảng ma trận xoay là Pattern Matrix hoặc Rotated Component Matrix từ output SPSS để đưa vào plugin. Trường hợp này mình đang chạy chung EFA cho toàn bộ các yếu tố trong mô hình để lấy hết toàn bộ biến đưa vào AMOS cho nhanh, nếu có xáo trộn cấu trúc thì mình sẽ dùng công cụ thủ công để kéo thả biến lại cho đúng.
Với mô hình này, cách chạy EFA phù hợp nhất đó là chia làm 3 lần chạy: lần 1 gồm QC-QH-KM-BH, lần 2 chỉ gồm NB, lần 3 chỉ gồm TT. Do EFA chạy riêng như vậy ma trận xoay sẽ không có đủ biến để đưa cùng một lượt vào diagram CFA. Lúc này chúng ta lại dùng tới công cụ thủ công để thêm các cấu trúc biến còn thiếu vào.

Copy bảng ma trận xoay Pattern Matrix hoặc Rotated Component Matrix dán vào cửa sổ Pattern Matrix Input, nhấp vào Create Diagram.

AMOS sẽ tự động tạo ra hình vẽ các biến, phần dư, các mối liên hệ.... một cách tự động, đều, đẹp thay vì chúng ta phải vẽ thủ công khi không có plugin Pattern Matrix Builder.

Tiến hành đổi các tên biến tiền ẩn 1,2,3,4,5... thành ký hiệu nhân tố cho dễ đọc kết quả.

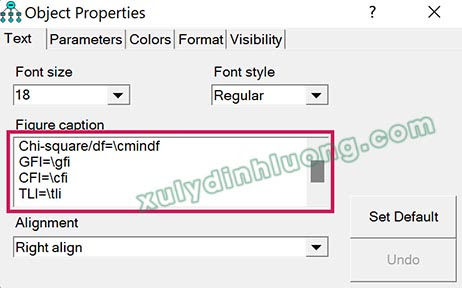
Chèn các macro để xem nhanh các chỉ số model fit. Cách thức thực hiện như sau. Tại giao diện AMOS, chọn vào biểu tượng Figure Captions (màu vàng có chữ Title).

Sau đó nhấp vào vùng trống trên diagram, cửa sổ Object Properties xuất hiện. Nhập macro chỉ số model fit vào mục Figure caption. Các bạn có thể tùy chỉnh kích thước chữ của macro, canh lề macro tại mục Font size và Alignment. Một số chỉ số model fit hay dùng như sau:

Sau khi chèn xong macro, hãy lưu lại file CFA bằng cách nhấn Ctrl + S hoặc vào File > Save.
Sau khi đã lưu file, chọn vào biểu tượng Analysis Properties.




3. Đọc kết quả phân tích CFA trên AMOS
3.1 Độ phù hợp mô hình (model fit)
Khi vẽ diagram CFA, chúng ta tạo ra shortcut các chỉ số về độ phù hợp mô hình ngay trên sơ đồ biểu diễn các đối tượng CFA để đọc nhanh một số chỉ số model fit quan trọng.

Để xem đầy đủ các chỉ số về độ phù hợp mô hình, chúng ta mở output CFA.
Nhấp vào mục Model Fit ở bên trái. Giao diện bên phải sẽ hiển thị toàn bộ các bảng liên quan đến độ phù hợp mô hình. Các chỉ số hiện trên shortcut ngoài diagram đều được lấy từ các bảng này.