Một biến được gọi là biến trung gian khi nó tham gia giải thích cho mối quan hệ giữa biến độc lập và phụ thuộc (Baron & Kenny, 1986). Xem thêm thông tin ba loại biến biến trung gian, điều tiết, kiểm soát tại bài viết này.

Mô hình biến trung gian cơ bản nhất gồm các biến và các mối tác động như sau:

Trong đó:
- c': Tác động trực tiếp direct effect từ X lên Y
- a*b: Tác động gián tiếp indirect effect từ X lên Y
- c: Tác động tổng hợp total effects từ X lên Y
Có những kỹ thuật xử lý biến trung gian khác nhau theo công trình nghiên cứu của các tác giả khác nhau. Dưới đây là hai kỹ thuật được sử dụng phổ biến cho tới hiện tại. Mỗi kỹ thuật có cách thức tiếp cận khái niệm biến trung gian và cơ chế xác định mối quan hệ trung gian khác nhau.
1. Xử lý biến trung gian mediator bằng Sobel Test
Theo Baron & Kenny (1986), một biến được xác định là đóng vai trò trung gian nếu thỏa mãn cùng lúc 3 điều kiện sau đây:
- Điều kiện 1: Biến độc lập có tác động lên biến trung gian (a ≠ 0).
- Điều kiện 2: Biến trung gian có tác động lên biến phụ thuộc (b ≠ 0).
- Điều kiện 3: Khi điều kiện 1 và 2 thỏa mãn, sự xuất hiện của biến trung gian sẽ làm giảm sự tác động từ biến độc lập lên biến phụ thuộc (c' < c), trong đó c là hệ số hồi quy từ X lên Y khi chưa có sự hiện diện của biến trung gian M.
Để kiểm tra một biến trung gian có thỏa được 3 điều kiện ở trên hay không, chúng ta sẽ thực hiện 3 phép hồi quy như sau:
1. Hồi quy đơn: X → M: Để biết biến độc lập có tác động lên biến trung gian hay không (điều kiện 1). Kết quả mong đợi là sig kiểm định t của biến X nhỏ hơn 0.05.
M = hằng số 1 + aX + e1
2. Hồi quy bội: X, M → Y: Để biết biến trung gian có tác động lên biến phụ thuộc hay không (điều kiện 2). Kết quả mong đợi là sig kiểm định t của biến M nhỏ hơn 0.05.
Y = hằng số 2 + c'X + bM + e2
3. Hồi quy đơn: X → Y: Để biết sự xuất hiện của biến trung gian có làm giảm sự tác động từ biến độc lập lên biến phụ thuộc hay không. Kết quả mong đợi là hệ số c' < c.
Y = hằng số 3 + cX + e3
Nếu 1 trong 3 điều kiện trên bị vi phạm, biến M không đóng vai trò trung gian can thiệp vào sự tác động từ X lên Y.
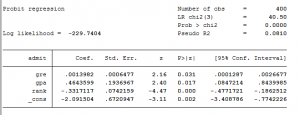
Trên cơ sở lý thuyết ở trên, chúng ta sẽ đi vào thực hiện đánh giá quan hệ trung gian bằng Sobel Test (Sobel, 1982) trên SPSS bằng cách giải quyết lần lượt từng hồi quy. Các bạn có thể tải tập dữ liệu thực hành tại đây, sau khi tải về các bạn giải nén để mở tệp tin Mediation File.sav thực hành.
Tập dữ liệu này sẽ gồm 3 biến X, M, Y tương ứng biến độc lập, trung gian, phụ thuộc. Biến độc lập là chất lượng dịch vụ, biến trung gian là sự hài lòng và biến phụ thuộc là ý định quay lại. Cả 3 biến đều được đánh giá bằng thang đo Likert 5 mức độ. Thực hiện phân tích biến trung gian bằng Sobel Test để xem Sự hài lòng có vai trò trung gian tác động lên mối quan hệ giữa Chất lượng dịch vụ với Ý định quay lại của khách hàng hay không.

Bước 1: Thực hiện hồi quy đơn X → M
Xem cách thực hiện hồi quy trên SPSS tại bài viết này. Chúng ta có sig kiểm định t của biến X bằng 0.000 < 0.05, biến X có tác động lên M. Hệ số tác động chưa chuẩn hóa và sai số chuẩn của X lần lượt: a = 0.305 và sa = 0.026 (các ký hiệu a, sa chúng ta sẽ dùng ở Sobel Test).

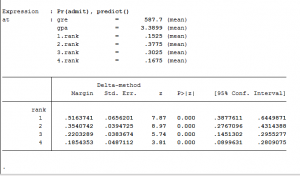
Bước 2: Thực hiện hồi quy bội X, M → Y
Chúng ta có sig kiểm định t của biến M bằng 0.000 < 0.05, biến M có tác động lên Y. Hệ số tác động chưa chuẩn hóa và sai số chuẩn của M lần lượt: b = 0.104 và sb = 0.027. Hệ số tác động chưa chuẩn hóa của X trong phép hồi quy này là c' = 0.626.

Bước 3: Thực hiện hồi quy đơn X → Y
Chúng ta có hệ số tác động chưa chuẩn hóa c = 0.657 > c' = 0.626, điều này cho thấy biến trung gian M đã làm giảm tác động của biến độc lập lên biến phụ thuộc. Tại đây, theo lý thuyết của Barron (1986) chúng ta sẽ kết luận biến M đóng vai trò trung gian tác động lên mối quan hệ của X và Y.

Hiệu số c - c' = 0.657 - 0.626 = 0.031 (cũng chính bằng tích số a*b) cho chúng ta thấy có sự khác biệt. Tuy nhiên, sự khác biệt này có ý nghĩa thống kê hay không, c lớn hơn c' có ý nghĩa thống kê hay không, chúng ta cần phải thực hiện kiểm định t để đánh giá. Phép kiểm định t đánh giá hiệu số c - c' có nghĩa thống kê hay không được gọi là Sobel Test (xem thêm tại đây). Do đó, chúng ta sẽ tiếp tục thực hiện bước 4.
Bước 4: Đánh giá sự khác biệt c - c' bằng Sobel Test.
SPSS không tích hợp sẵn Sobel Test, chúng ta sẽ thực hiện kiểm định tại website này. Sau khi truy cập vào website, chúng ta sẽ chú ý tới phần Input với 4 giá trị cần khai báo đầu vào là a, b, sa, sb. Với:
- a, sa: lần lượt là hệ số hồi quy chưa chuẩn hóa và sai số chuẩn của X trong phương trình hồi quy đơn X → M.
- b, sb: lần lượt là hệ số hồi quy chưa chuẩn hóa và sai số chuẩn của M trong phương trình hồi quy bội X, M → Y.
Nhập 4 giá trị a, b, sa, sb tương ứng vào các ô trên bảng Sobel Test, sau đó nhấn vào Calculate để tiến hành phân tích. Chúng ta sẽ đọc kết quả giá trị p-value ở phần bôi vàng.

Giá trị sig (p-value) của kiểm định Sobel bằng 0.000 < 0.05, như vậy M là biến trung gian tác động lên mối quan hệ từ X lên Y.
2. Xử lý biến trung gian mediator bằng Bootstrap với macro PROCESS
Với lý thuyết của Baron & Kenny (1986) về biến trung gian và mối tác động trung gian, một điều kiện cần đó là biến độc lập X phải có sự tác động lên biến phụ thuộc Y (tác động tổng hợp total effect - hệ số c phải có ý nghĩa).
Trong đó:
- c': Tác động trực tiếp direct effect từ X lên Y
- a*b: Tác động gián tiếp indirect effect từ X lên Y
- c: Tác động tổng hợp total effects từ X lên Y
Tuy nhiên, một số tác giả (Collins, Graham, & Flaherty, 1998; Judd & Kenny, 1981; Kenny et al., 1998; MacKinnon, 1994, 2000; MacKinnon, Krull, & Lockwood, 2000; Shrout & Bolger, 2002) đã đưa ra tranh cãi rằng, mối tác động tổng hợp total effects không nhất thiết phải có ý nghĩa thì mới có mối quan hệ trung gian. Do đó, chúng ta cần có một hướng đánh giá mối quan hệ trung gian chính xác hơn.
Bootstrapping là một kỹ thuật liên quan đến việc lấy mẫu lặp lại từ tập dữ liệu mẫu và ước tính tác động gián tiếp indirect (tích số a*b) trong mỗi tập dữ liệu được lấy mẫu lại. Bằng cách lặp lại quá trình này, phân phối của tích số a*b được hình thành và tạo nên khoảng tin cậy (Confidence Interval) của mối quan hệ gián tiếp indirect effects (Preacher and Hayes, 2004).
Nhiều nghiên cứu đã chứng minh kỹ thuật Bootstrapping tốt hơn Sobel Test và các kỹ thuật khác khi đánh giá mối quan hệ trung gian (Williams & MacKinnon, 2008; Preacher & Hayes, 2008; Zhao, Lynch & Chen, 2010). Trong khi Sobel Test yêu cầu cỡ mẫu lớn và dữ liệu cần có phân phối chuẩn thì Bootstrapping khắc phục được các hạn chế này (Hayes, 2009). Chính vì vậy mà hiện nay, kỹ thuật xử lý biến trung gian bằng Bootstrap được sử dụng phổ biến hơn so với Sobel Test.
ư
 Xem thêm: Xử lý biến điều tiết moderator trong SPSS
Xem thêm: Xử lý biến điều tiết moderator trong SPSS
Để thực hiện phân tích biến trung gian bằng Bootstrap trên SPSS, chúng ta sẽ dụng Hayes Process Macro. Các bạn tải Macro này tại https://www.processmacro.org/download.html, cách tải và cài đặt vào SPSS, các bạn xem ở video bên dưới.
Mở tệp dữ liệu SPSS cần chạy phân tích trung gian, vào Analyze > Regression > PROCESS v3.5 by Andrew F. Hayes (macro cập nhật liên tục theo thời gian, do vậy số phiên bản 3.5 có thể thay đổi).

Cửa sổ PROCESS xuất hiện, chúng ta đưa biến phụ thuộc vào Y variable, biến độc lập vào X variable, biến trung gian vào Mediator(s). Nếu có nhiều biến trung gian cùng tác động lên mối quan hệ X, Y, chúng ta có thể đưa tất cả vào cùng lúc. Chọn các tùy chọn giống như mục số 2, sau đó nhấp vào Options mục 3.

Trong Options, tích vào 2 lựa chọn ở mục 1 và thiết lập mục 2 như ảnh. Nhấp Continue để quay lại cửa sổ ban đầu, sau đó nhấp OK để xuất kết quả ra Output.

Tương tự như Sobel Test, Macro PROCESS cũng xuất kết quả các phép hồi quy X → M (hồi quy 1) và X, M → Y (hồi quy 2). Bởi vì mỗi lần chạy Bootstrap, phần mềm sẽ lấy mẫu khác nhau nên kết quả có sự sai biệt giữa ảnh bên dưới với phần thực hành là bình thường, không phải lỗi.


(Kết quả phép hồi quy từ X, M lên Y)
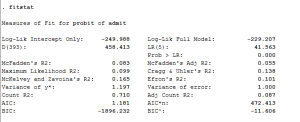
Chúng ta quan tâm nhiều nhất vào mối quan hệ gián tiếp của X lên Y. Do vậy, cần tập trung vào bảng TOTAL, DIRECT AND INDIRECT EFFECTS OF X ON Y.
- Total effect of X on Y: Tổng tác động từ X lên Y (hệ số c)
- Direct effect of X on Y: Tác động trực tiếp từ X lên Y (hệ số c')
- Indirect effect(s) of X on Y: Tác động gián tiếp từ X lên Y qua M (tích số a*b)

Phần Indirect effects chúng ta sẽ đánh giá có sự tác động gián tiếp hay không dựa vào khoảng tin cậy phép bootstrap cho tích số a*b .

- Nếu khoảng tin cậy phép bootstrap tích số a*b chứa giá trị 0, chúng ta kết luận không có tác động gián tiếp từ X lên Y.
- Nếu khoảng tin cậy phép bootstrap tích số a*b không chứa giá trị 0, chúng ta kết luận có tác động gián tiếp từ X lên Y.
Cụ thể trong ví dụ thực hành, từ đầu chúng ta chọn độ tin cậy là 95%, kết quả cho gá trị dưới BootLLCI (Lower-Level Confidence Interval) bằng 0.0139 và giá trị trên BootULCI (Upper-Level Confidence Interval) bằng 0.0509. Khoảng tin cậy [0.0139; 0.0509] không bao gồm giá trị 0, như vậy có tác động gián tiếp từ X lên Y qua M với mức tác động là 0.0317. Như vậy, biến M có vai trò trung gian tác động lên mối quan hệ từ X tới Y.